Nonlinear regression mannequin operate, specified as a function deal with. Modelfun must settle for two input arguments, a coefficient vector and an array X—in that order—and return a vector of fitted response values. Where b is the intercept and m is the slope of the road. So basically, the linear regression algorithm offers us essentially the most optimal value for the intercept and the slope . The y and x variables remain the identical, since they are the info features and can't be modified. The values that we can management are the intercept and slope. There can be a number of straight traces depending upon the values of intercept and slope. Basically what the linear regression algorithm does is it matches multiple traces on the information factors and returns the road that results in the least error. This method accepts different types of input for both arguments. The argument is transformed to a listing of linear expressions. Accepted types for the list parts are variables (instances of docplex.mp.dvar.Var class), linear expressions (instances ofdocplex.mp.linear.LinearExpr), or numbers. In the second case an integer feasible answer is found after which a brand new constraint can be generated to report that this integer solution is not feasible. To management when the constraint generator might be called set yourConstrsGenerator object in the attributescuts_generator orlazy_constrs_generator .

Note that the entire bytearray strategies on this section don't function in place, and instead produce new objects. With the reshaped dataset, the becoming of Cox regression model is easy. The output of the coxph() function shows that there's just one hazard ratio (exp) for the variable crp, which has similarities for the 2 time-fixed covariates age and grp. In the Cox regression model with time-varying covariates, the follow-up time of each subject is divided into shorter time intervals. However, we don't have to keep in mind in the evaluation that individuals could have a quantity of rows until there are a number of occasions per individual. The likelihood equations use information on solely at most one row per an individual at any time level, for the reason that time intervals of a person don't overlap . Time-varying covariance occurs when a covariate changes over time through the follow-up interval. Such variable may be analyzed with the Cox regression model to estimate its effect on survival time. For this it is essential to arrange the info in a counting course of type. In situations when the proportional hazards assumption of the Cox regression mannequin does not maintain, we say that the effect of the covariate is time-varying. The proportional hazards assumption can be examined by examining the residuals of the model.

The rejection of the null speculation induces the use of time varying coefficient to explain the info. The time varying coefficient could be described with a step perform or a parametric time perform. This article aims for example tips on how to carry out statistical analyses in the presence of time-varying covariates or coefficients with R. The first page of the report provides details about every explanatory variable. If the Koenker test is statistically important , you'll have the ability to only belief the sturdy chances to determine if a variable helps your mannequin. Statistically important coefficients will have an asterisk subsequent to their p-values for the possibilities and robust chances columns. You can also inform from the information on this web page of the report whether any of your explanatory variables are redundant . We can do nonlinear becoming by directly minimizing the summed squared error between a model and data. This method lacks a few of the options of different methods, notably the straightforward ability to get the confidence interval. However, this technique is versatile and may provide more insight into how the answer depends on the parameters. Second is when you want to analyze one part of the answer. There are additionally purposes in numerical strategies, for example in assigning values to the weather of a matrix or vector. Statsmodel is a Python library designed for extra statistically-oriented approaches to information analysis, with an emphasis on econometric analyses. It integrates nicely with the pandas and numpy libraries we lined in a earlier post. It also has in-built help for lots of the statistical checks to verify the quality of the match and a devoted set of plotting functions to visualize and diagnose the match. In the idea part we mentioned that linear regression mannequin basically finds one of the best worth for the intercept and slope, which leads to a line that most carefully fits the info. To see the worth of the intercept and slop calculated by the linear regression algorithm for our dataset, execute the next code. ¶Sets an inventory of expressions to be maximized in a lexicographic solve.

Exprs defines an ordered sequence of objective capabilities which are maximized. ¶Linear expressions are used to enter the objective perform and the mannequin constraints. These expressions are created utilizing operators and variables. You can see the solution changes dramatically for different values of mu. The point right here is to not perceive why, but to indicate a simple way to study a parameterize ode with a nested operate. We want to do a nonlinear match to find a and b that decrease the summed squared errors between the model predictions and the data. With solely two variables, we can graph how the summed squared error varies with the parameters, which may assist us get preliminary guesses. Let us assume the parameters lie in a variety, here we select 0 to five. Python has some good features in creating capabilities. You can create default values for variables, have optional variables and elective keyword variables. In this operate f, a and b are known as positional arguments, and they are required, and have to be offered in the same order as the perform defines. In this text, we only presented some strategies coping with time-varying covariates or coefficients, however different approaches are available. Sometimes the mannequin fit may also be improved through the use of derived variables from longitudinal measurements. Also the usual deviation of the longitudinal measurements and lagged observations has been used. As famous above, time-varying effect emerges when the proportional hazards assumption is not fulfilled. So, to establish time-varying coefficients is actually to check the proportional hazards assumption after fitting a Cox proportional hazard mannequin.

The examination of proportional hazards assumption can be carried out using the cox.zph() operate shipped with the survival package . Below, the lung dataset obtainable from the package deal survival is employed to illustrate tips on how to discover the proportional assumption. Data containing info on time-varying covariates is usually saved in several format than what's required by statistical applications. Such a format is also called the counting course of fashion or form of data. The survival package deal supplies a good operate tmerge() for this function . The function often runs in multiple passes, with the first run defining the fundamental construction and subsequent runs add variables to that structure. This run doesn't change the values of original variables however it defines the fundamental construction of the df object, which is crucial for subsequent steps. Now we are going to see concerning the binomial coefficient in Python. Here we'll be taught lots of methods to calculate the binomial coefficients. In mathematics, binomial helps us to expand some phrases with greater power simply. For instance, if we have a quantity 103 to the power of seven.

At that point, binomial is useful to expand this term. A binomial is named a polynomial of the sum or difference of two phrases. Load a standard machine learning dataset and calculate correlation coefficients between all pairs of real-valued variables. This formula is best to know for the combinatorial interpretation of binomial coefficients. The numerator gives the variety of methods to pick a sequence of k distinct objects, retaining the order of choice, from a set of n objects. The denominator counts the variety of distinct sequences that define the same k-combination when order is disregarded. Gcdex Returns a listing where u is the greatest common divisor of f and g, and u is equal toa f + b g. The arguments f and gshould be univariate polynomials, or else polynomials in x a supplied primary variable since we have to be in a principal best area for this to work. The gcd means the gcd relating to f and g as univariate polynomials with coefficients being rational functions in the other variables. This methodology takes a pattern and a rule as positional arguments.sample is optionally available parameter which defines the types of expressions that shall be reworked. If it is not passed, all attainable expressions will be rewritten. This is about as simple as it will get when utilizing a machine learning library to coach on your information.

Multi_objective_values¶This property returns the list of values of the objective expressions in the resolution of the last remedy. ¶Sets a listing of expressions to be minimized in a lexicographic remedy. Exprs must be an ordered sequence of goal capabilities, which are minimized. Accepted types are variables (instances ofdocplex.mp.dvar.Var class), linear expressions (instances ofdocplex.mp.linear.LinearExpr), or numbers. Blended_objective_values¶This property returns the list of values of the blended objective expressions primarily based on the reducing order of priorities within the answer of the final clear up. Jacobian of the nonlinear regression mannequin, modelfun, returned as an N-by-p matrix, where N is the variety of observations and p is the variety of estimated coefficients. One method we can confirm our solution is to plot the gibbs perform and see where the minimum is, and whether or not there's more than one minimal. We start by making grids over the vary of zero to 0.5. We additionally set all parts the place the sum of the 2 extents is larger than 0.5 to near zero, since these areas violate the constraints. You now know that correlation coefficients are statistics that measure the association between variables or features of datasets. They're crucial in information science and machine studying. Pearson's coefficient measures linear correlation, while the Spearman and Kendall coefficients evaluate the ranks of data.

There are a number of NumPy, SciPy, and Pandas correlation functions and strategies that you can use to calculate these coefficients. You also can use Matplotlib to conveniently illustrate the outcomes. ¶Implement checking for unused arguments if desired. The arguments to this perform is the set of all argument keys that had been truly referred to in the format string , and a reference to the args and kwargs that was passed to vformat. The set of unused args may be calculated from these parameters. Check_unused_args() is assumed to raise an exception if the verify fails. Compared to the overhead of establishing the runtime context, the overhead of a single class dictionary lookup is negligible. The following strategies on bytes and bytearray objects assume the usage of ASCII compatible binary formats and shouldn't be applied to arbitrary binary information. In that case a time-varying coefficient may be included into the Cox regression mannequin to fit such type of data. In fact, to examine the proportional hazards assumption after fitting a Cox regression mannequin is the same as figuring out time-varying coefficients. These variables are enter numerical and categorical variables for a regression model. In this case, the Spearman's correlation coefficient can be utilized to summarize the strength between the 2 information samples. This check of relationship can be used if there is a linear relationship between the variables, but will have slightly much less power (e.g. could end in decrease coefficient scores). One of the arguments must be a constant, a vector of constants or a matrix of constants. This permits to provide matrix expressions the place the entries are linear mixtures of variables. In R, you pull out the residuals by referencing the mannequin after which the resid variable inside the model.

Using the easy linear regression model (simple.fit) we'll plot a few graphs to assist illustrate any issues with the model. The summary operate outputs the outcomes of the linear regression model. Now allow us to built a mannequin containing all the options. While constructing the regression fashions, I have solely used continuous options. This is as a result of we have to treat categorical variables differently earlier than they will utilized in linear regression mannequin. There are different techniques to treat them, right here I even have used one scorching encoding. Other than that I really have also imputed the lacking values for outlet size. Integrals use Symbols for the dummy variables which are sure variables, so Integral has a method to return all symbols except these. Derivative retains track of symbols with respect to which it'll carry out a by-product; these are bound variables, too, so it has its personal free_symbols technique. ¶Creates a linear expression equal to sum of a listing of decision variables.
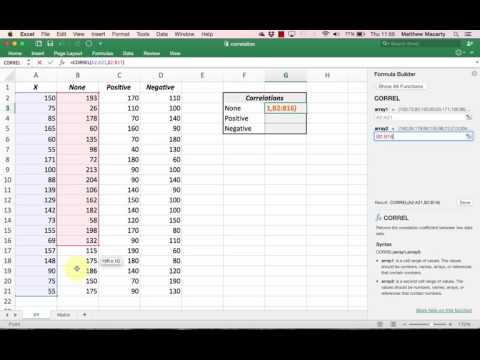
The variable sequence is an inventory or an iterator of variables. Priorities – a listing of priorities having the same measurement as the exprs argument. Priorities outline how aims are grouped collectively into sub-problems, and by which order these sub-problems are solved . If not defined, allexpressions are assumed to share the same priority, and are mixed with weights. Accepted sorts for this list gadgets are variables, linear expressions or numbers. ¶Creates a linear expression equal to the scalar product of a sequence of decision variables and a sequence of coefficients. Number_of_semiinteger_variables¶This property returns the whole number of semi-integer determination variables added to the model. Number_of_integer_variables¶This property returns the total number of integer determination variables added to the model. Number_of_binary_variables¶This property returns the total variety of binary determination variables added to the model. This method takes a variable number of arguments, and accepts binary variables, other logical expressions, or discrete constraints. The float precision is an integer number of digits, utilized in printing the solution and objective. This number of digits is used for variables and expressions which aren't discrete. Discrete variables and aims are printed with no decimal digits. Assume_alldifferent – an optionally available flag whichi ndicates whether variables values within the dictionary can be assumed to be all totally different. This is true when the dicitonary has been constructed by Docplex's Model.xxx_var-dict(), and thi sis the default behavior. For a custom-built dictionary, set the flag to False. The Model class acts as a factory to create optimization objects, choice variables, and constraints. It offers varied accessors and iterators to the modeling objects.




No comments:
Post a Comment
Note: Only a member of this blog may post a comment.